

Vous avez sûrement déjà discuté avec une intelligence artificielle, que ce soit via ChatGPT, un assistant vocal ou une IA intégrée dans une application. Vous tapez une phrase, vous appuyez sur « Envoyer »… et une réponse surgit, souvent impressionnante, parfois même bluffante.
Mais que se passe-t-il entre le moment où vous envoyez votre message (prompt) et celui où l’IA vous répond ?
Dans cet article, on vous embarque dans un voyage simplifié et pédagogique au cœur du cerveau d’une IA. Promis, pas besoin d’avoir fait maths sup pour comprendre. Suivez le guide.
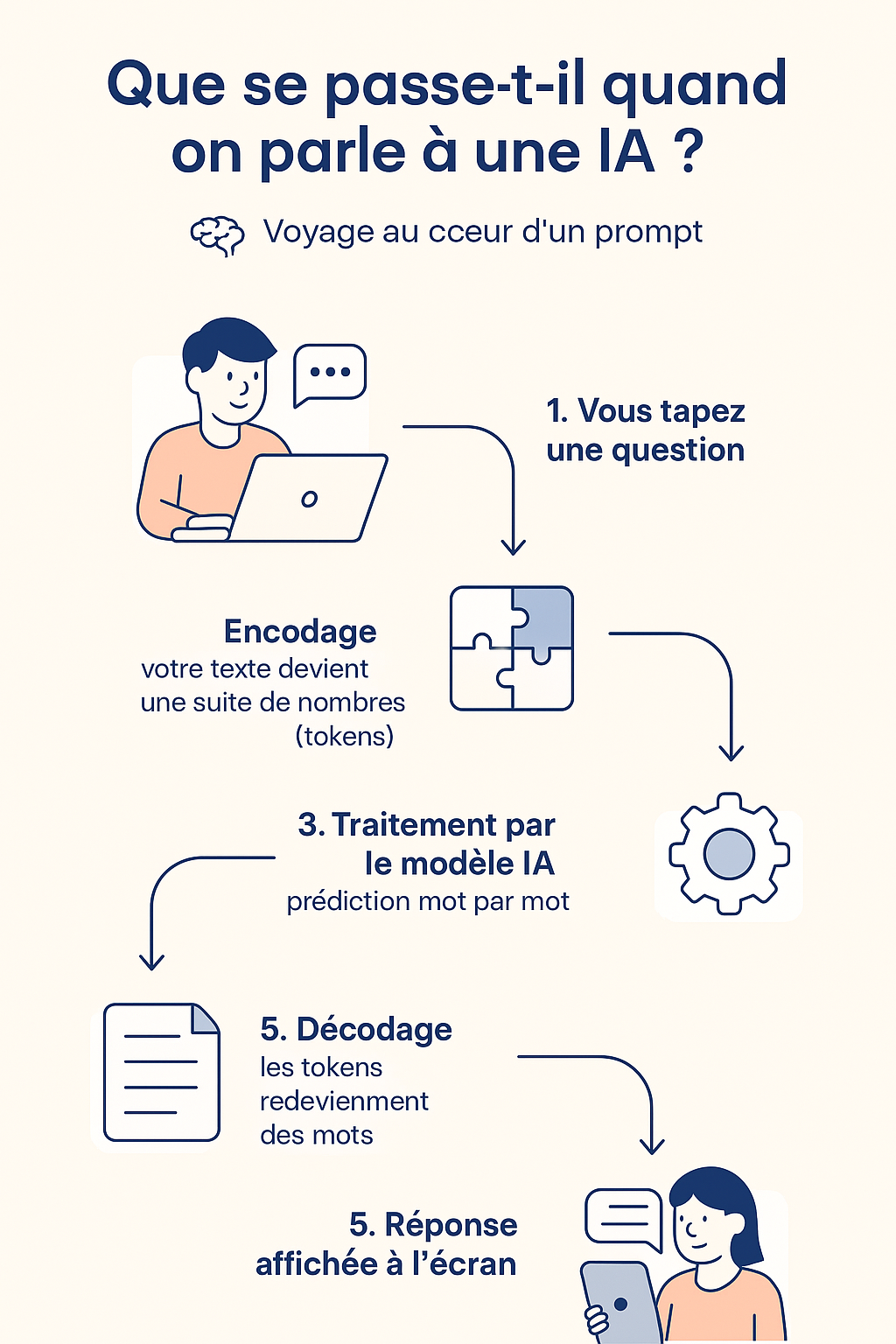
📥 Étape 1 : Vous écrivez un « prompt » (une requête)
Tout commence avec vous.
👉 Exemple :
« Donne-moi une recette simple de gâteau au chocolat. »
Ce message s’appelle un prompt. C’est une instruction, une question ou une demande adressée à l’IA. Mais à ce stade, il s’agit simplement de texte brut.
🧬 Étape 2 : Le texte est encodé en nombres (tokenisation)
Les IA ne comprennent pas directement le texte comme nous. Elles ne voient ni les lettres, ni les mots, mais des nombres.
Comment ça fonctionne ?
L’IA utilise un encodeur (appelé tokenizer) pour convertir le texte en « tokens » : des unités de sens qui peuvent être des mots, des syllabes ou des fragments de mots.
👉 Exemple : Le prompt
« Donne-moi une recette simple de gâteau au chocolat. »
peut être transformé en quelque chose comme :[2049, 1098, 1325, 5011, 67, 7823, 1250, 32, 9003]
Chaque nombre représente un morceau de mot ou un mot entier.
📌 Pourquoi des nombres ?
Parce que les modèles de langage sont des machines mathématiques. Ils ne travaillent qu’avec des vecteurs numériques. Il faut donc traduire les mots en chiffres avant de pouvoir les traiter.
🧠 Étape 3 : L’IA prédit la suite mot par mot
Une fois le prompt encodé, on entre dans le cœur du système : le modèle de langage, une énorme machine mathématique basée sur des neurones artificiels.
L’IA ne sait pas « répondre » au sens humain du terme. Elle devine mot après mot ce qui devrait venir ensuite. C’est une prédiction statistique.
Concrètement :
- Elle reçoit les tokens du prompt.
- Elle calcule (à l’aide de millions, voire milliards de paramètres) quelle est la probabilité de chaque mot possible à suivre.
- Elle choisit le plus probable (ou un mot parmi les plus probables, selon la température du modèle).
- Elle ajoute ce mot à la séquence, et recommence avec cette nouvelle phrase.
👉 Exemple : Elle peut commencer par générer :
“Voici une recette simple pour un délicieux gâteau au chocolat :”
Puis :
“Ingrédients : 200g de chocolat noir, 100g de sucre…”
Et elle continue ainsi jusqu’à ce que la réponse soit jugée terminée.
🧠 Zoom sur le modèle : une « machine à compléter des phrases »
Le fonctionnement repose sur un principe simple mais puissant :
Compléter le texte, en devinant ce qui vient ensuite.
Ce mécanisme est rendu possible grâce à un type de réseau de neurones très performant appelé Transformers.
Chaque neurone artificiel ne comprend rien à la langue, mais en empilant des couches de calculs, l’IA apprend à :
- reconnaître des structures grammaticales ;
- comprendre le contexte ;
- imiter des styles d’écriture ;
- gérer des connaissances encyclopédiques.
…
⚠️ Important : L’IA ne comprend pas vraiment ce que vous dites. Elle imite statistiquement ce qu’un humain pourrait répondre à une phrase similaire, en se basant sur les milliards de textes qu’elle a « lus » pendant son entraînement.
💾 Étape 4 : L’IA génère la réponse… toujours en tokens
Quand l’IA a fini de prédire les tokens de la réponse, elle les garde sous forme de nombres.
👉 Par exemple, la réponse peut être quelque chose comme :[4501, 2199, 1325, 1055, 9003, 11, 9021, 221]
Il faut donc faire l’opération inverse de l’encodage initial pour retrouver du texte lisible.
🔁 Étape 5 : Décodage et affichage
C’est l’encodeur inverse (appelé decodeur) qui transforme les tokens générés en texte.
👉 On retrouve notre réponse textuelle :
« Voici une recette simple pour un délicieux gâteau au chocolat :… »
C’est ce texte final qui s’affiche dans l’interface utilisateur (chat, console, application mobile, etc.).
🔄 Que fait l’IA si je corrige ou précise ma question ?
L’IA considère tout l’historique de la conversation comme un seul long texte.
Elle revoit le contexte précédent, y ajoute votre nouvelle instruction, puis recommence le processus :
- Tokenisation du message complet (ancien + nouveau).
- Calcul de la suite la plus probable.
- Génération mot par mot de la réponse.
- Décodage du résultat.
🧮 Et tout ça prend… moins d’une seconde ?
Oui. Sur des serveurs puissants ou des machines locales avec un bon GPU, ce processus prend quelques millisecondes à quelques secondes, selon :
- la taille du modèle (GPT-2, GPT-3, LLaMA, Mistral, etc.) ;
- la longueur de la réponse ;
- la complexité de la question.
🔐 Où vont mes données ? (Bonus : la confidentialité)
Lorsque vous utilisez une IA dans le cloud (ChatGPT, Bard, etc.), vos prompts sont envoyés sur des serveurs distants. Cela peut poser des questions de :
- confidentialité,
- propriété des données,
- sécurité (fuites, piratages),
- conformité RGPD.
Solution possible : utiliser une IA en local, comme OLLAMA ou LM Studio. (on en parle ici)
Avantages :
- Vos données ne quittent jamais votre machine ;
- Pas de dépendance réseau ;
- Vous gardez le contrôle total.
🧵 Récapitulatif visuel : le voyage d’un prompt
✨ Conclusion : une magie mathématique (presque) compréhensible
Même si l’IA semble magique, son fonctionnement repose sur une succession d’opérations mathématiques bien définies. Chaque fois que vous interagissez avec un modèle de langage, une danse numérique s’orchestre en coulisses pour produire une réponse cohérente, rapide et souvent bluffante.
Et maintenant que vous savez ce qui se passe derrière l’écran…
👉 Peut-être verrez-vous vos prompts d’un autre œil !